Algunas notas que me han servido para entender que es keda y como funciona…
Proposito
El objetivo de esta PoC, es en última instancia, poder escalar usando HPA, en función de metricas no estandard, para lo que se han visto distintas aproximaciones.
Detalle
Contexto
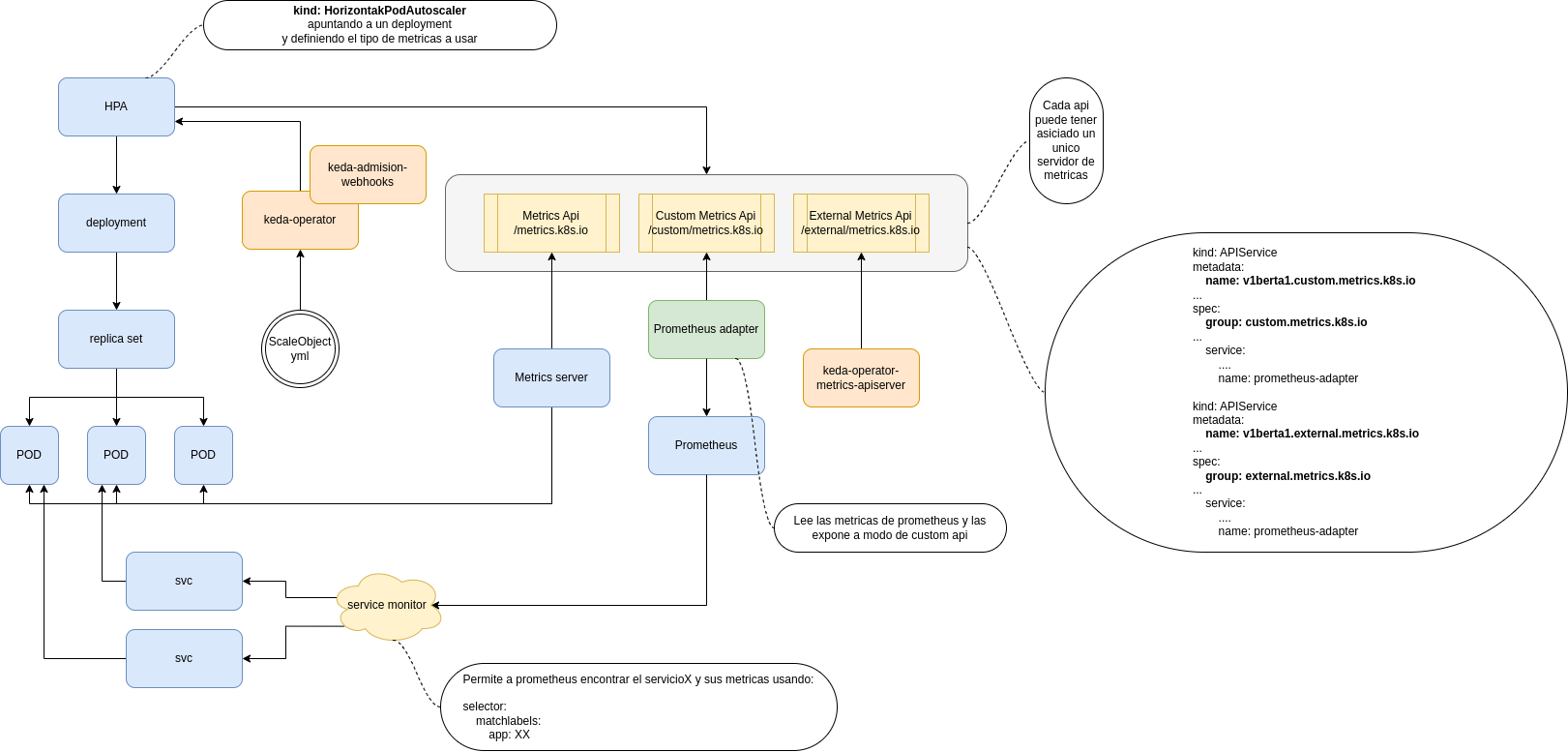
Analizaremos brevemente el funcionamiento de HPA, metric-server y justificaremos la decisión del uso de Keda. Para poder explicar los distintos puntos nos basaremos en el siguiente diagrama.
Notas: Algunos de los componentes implicados o testados.
metric-server -> Implementa la especificación de metrics Api y obtiene métricas base, CPU y MEM
HPA -> Lee la api de métricas de K8s para poder escalar pods.
prometheus-adapter -> Expone las métricas de prometheus a la api de métricas de K8s. La complejidad reside en identificar y tener en prometheus la métrica deseada y exponerla correctamente para ser usada por el HPA.
KEDA -> (Kubernetes-based Event Driven Autoscaler) Según la documentación oficial, es un componente liviano y de un solo propósito que se puede agregar a cualquier clúster de Kubernetes. KEDA funciona junto con componentes estándar de Kubernetes, HPA y metric-server A partir de desplegar un ScaleObject keda se encarga de:
- Generar y exponer la metrica correcta en external-metric-api, levanta su propio server de métricas y se expone en external metrics
- Crear el HPA necesario según la conf dada en el ScaleObject –> No reemplazan el metric-server de kubernetes. Para escalado en base a CPU y MEM usan el estándar
Facilita el uso de HPA, ¿como se llama la métrica?¿he hecho relabeling de la metrica para que sea accesible en el NS?… ¿que pasa si necesito métricas de mas de 3 servers? operador, leo crd etc
Componentes de KEDA
- keda-operator –> Escucha la creación de recursos de los CRD y activa y desactiva los deployments para que escalen
- keda-operator-metrics-apiserver –> Expone métricas via api al HPA
- keda-admission-webhooks –> Valida configuraciones para evitar errores
- Ej. Varios ScaleObject apuntando a un mismo target
CRD’s de KEDA
- scaleobjects.keda.sh –> Escala deployments, statefulsets etc
- scaledjobs.keda.sh –> Crea replicas o escala jobs
- triggerauthentications.keda.sh –> Definir auth para acceder al origen de datos. Solo desde un NS especifico
- clustertriggerauthentications.keda.sh –> Definir auth para acceder al origen de datos. Desde todo el cluster.
Decisión
Hemos optados por seguir las pruebas con KEDA, principalmente por dos motivos. 1.- La facilidad de uso que aporta, de cara a obtener y usar HPA con métricas complejas. 2.- La limitación de k8s de poder asociar solo un servidor a cada una de las 3 apis, de modo que un agregador, nos da mayor flexibilidad en cuando al origen de datos.
Despliegue
Prueba local.
INSTALL KEDA & REDIS IN KIND
cd /GITHUB/homelab/create_Kind_K8s
make clean
make
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda --namespace keda --create-namespace
helm install redis oci://registry-1.docker.io/bitnamicharts/redis --namespace application --create-namespace
Ejemplos
Tenemos disponibles ejemplos para multitud de scalers en la documentación oficial. https://keda.sh/docs/2.10/scalers/
Escalado de Rabbit Con mas de 20 mensajes en la cola testqueue escala el deploy rabbitmq-deployment
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-scaledobject
namespace: default
spec:
scaleTargetRef:
name: rabbitmq-deployment
triggers:
- type: rabbitmq
metadata:
protocol: amqp
queueName: testqueue
mode: QueueLength
value: "20"
authenticationRef:
name: keda-trigger-auth-rabbitmq-conn
Links
https://keda.sh/docs/2.10/concepts/ http://blog.itaysk.com/2019/01/15/Kubernetes-metrics-and-monitoring https://www.youtube.com/watch?v=-8ebk4kFMTA